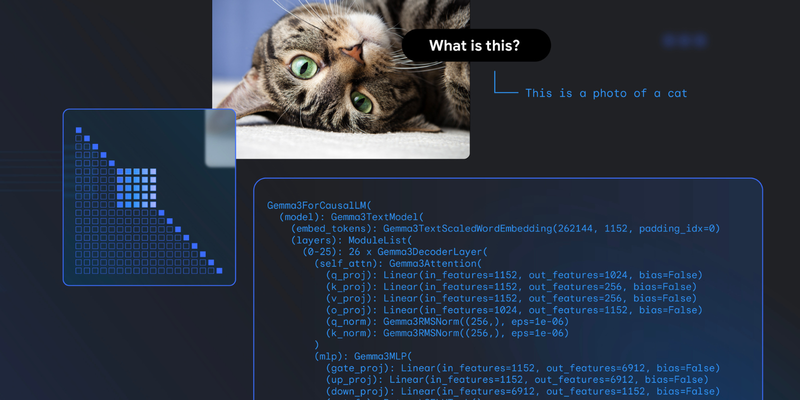
先日は、Gemma 3 と Gemma 3 QAT のリリースというエキサイティングな発表がありました。これらは、1 つのクラウド アクセラレータやデスクトップ アクセラレータで実行できる最先端のオープンモデル ファミリーです。本日はそれを受けて、AI を身近なものにするという私たちのビジョンをさらに前進させます。Gemma 3 はデベロッパーに強力な機能を提供していますが、そのビジョンを広げ、スマートフォン、タブレット、ノートパソコンといった毎日使うデバイスで直接動作する高機能リアルタイム AI に向かいます。
次世代のオンデバイス AI を実現し、Gemini Nano の機能向上をはじめとする多様なアプリケーションをサポートできるようにするため、新たに最先端のアーキテクチャを設計しました。この次世代の基盤は、Qualcomm Technologies、MediaTek、Samsung System LSI などのモバイル ハードウェアをリードする企業と密に連携して作成したものです。超高速なマルチモーダル AI 向けに最適化されており、真にパーソナルでプライベートな体験をオンデバイスで直接実現します。
Gemma 3n は、この画期的な共有アーキテクチャに基づいて開発された最初のオープンモデルです。デベロッパーの皆さんは、本日より早期プレビュー版としてこのテクノロジーを試すことができます。この高度なアーキテクチャは、次世代の Gemini Nano にも搭載されます。今年中には、Google アプリやオンデバイス エコシステムのさまざまな場所で、この機能が利用できるようになる予定です。この基盤は Android や Chrome などの主要プラットフォームで利用できるようになりますが、Gemma 3n を使うと、これをベースとして開発を始めることができます。
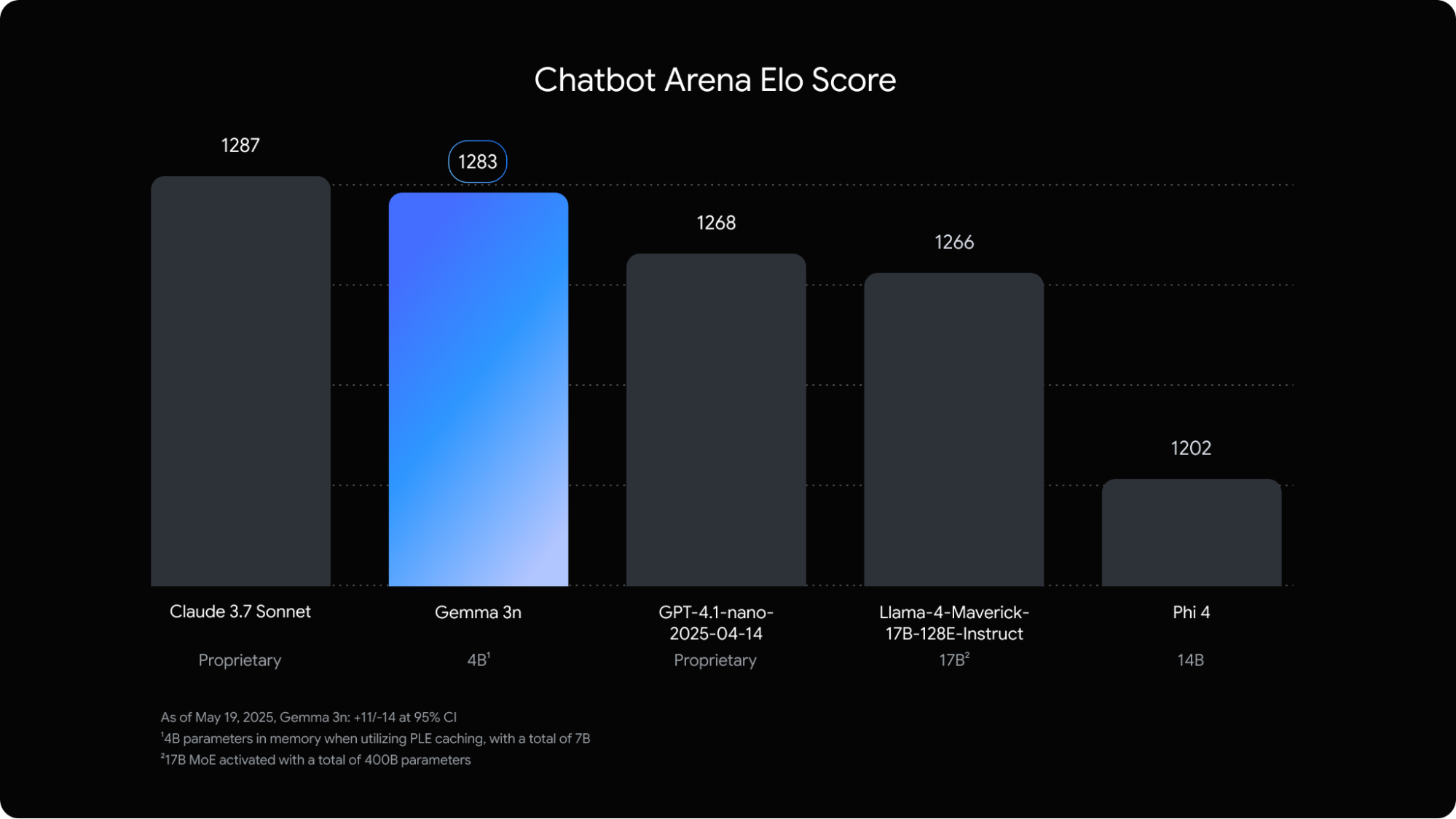
Gemma 3n では、RAM 使用量を大幅に削減する Per-Layer Embeddings(PLE)という Google DeepMind のイノベーションを活用しています。もともとのパラメータ数は 5B と 8B ですが、このイノベーションにより、2B や 4B のモデルに匹敵するメモリ オーバーヘッドで、それよりも大きなモデルを実行できます。モバイル デバイスで動かすことも、クラウドからのライブストリーミングを用いることもでき、モデルが動的に使用するメモリの量は、わずか 2GB または 3GB となります。詳しくは、ドキュメントをご覧ください。
このモバイルファーストのアーキテクチャ イノベーションは、今後、Gemini Nano を搭載した Android や Chrome で利用できるようになります。Gemma 3n では、オープンモデルのコア機能とこのイノベーションを早期プレビュー版として試すことができます。
この投稿では、Gemma 3n の新機能、責任ある開発へのアプローチ、そして今すぐプレビュー版にアクセスする方法について説明します。
Gemma 3n は、ローカルで実行される高速で低フットプリントな AI エクスペリエンス向けに設計されています。特徴は以下のとおりです。

デベロッパーは、Gemma 3n を利用して次のようなことを実現できます。移動しながらでもインテリジェントなアプリケーションを利用できるので、新たな潮流を生み出すことができます。
2. オーディオ、画像、動画、テキスト入力を組み合わせて理解を深め、状況に応じたテキストを生成できるようにする。すべての情報はオンデバイスで安全に処理される。
3. リアルタイム音声文字変換、翻訳、高度な音声駆動型インタラクションなど、オーディオ中心の高度なアプリケーションを開発する。
概要と、作成できるエクスペリエンスの種類を紹介します。
Link to Youtube Video (visible only when JS is disabled)
最も重要なのは、私たちの責任ある AI 開発への取り組みです。Gemma 3n は、すべての Gemma モデルと同じく、厳格な安全性評価、データ ガバナンス、安全ポリシーに合わせたファインチューニングが実施されています。私たちは、オープンモデルに対して慎重なリスク評価を行い、AI の進化に合わせて継続的に手法を改善しています。
うれしいことに、本日よりプレビュー版として Gemma 3n をお届けします。
初期アクセス(すぐに利用できます):
Gemma 3n は、最先端の効率的な AI を誰でも使えるようにすることに向けた次の一歩です。本日のプレビュー版から、このテクノロジーが徐々に利用できるようになります。皆さんがこれで何を開発するのか、とても楽しみです。
この発表と Google I/O 2025 のすべての最新情報は、5 月 22 日以降に io.google でご覧いただけます。